In this blog post, I will explore the saga pattern as a solution to the problem of implementing distributed transactions. I will discuss the context and problems that arise when working with distributed systems and how the saga pattern can help address these challenges. I will also go into the details of how to model sagas with Pub/Sub messages and provide a demo application written in Go to illustrate the concepts.
Below is a list of useful resources I used to learn about the saga pattern:
- Distributed transaction patterns for microservices compared
- Saga distributed transactions pattern
- Pattern: Saga
Table of contents
- Context and problem
- What is the saga pattern?
- Implement with Pub/Sub
- Actions
- Compensating actions
- Compensating actions
- Observability
- Implementation
Context and problem
Almost every system must perform multiple write operations outside of a database transaction at some point, particularly in a distributed system where services must communicate with each other while each service has its own database. However, the same problem can also occur outside of a distributed setting.
To demonstrate the problem, consider an example from a recent project where a system had to integrate with a third-party API that was rather unstable. The system had to perform the following sequence of operations:
- Create an invoice through the API, receiving the invoice's ID in the response.
- Make a second request to fetch the created invoice by its ID.
It might seem reasonable to assume that if the first POST request succeeds, the second GET
request will most likely not fail either. However, this was not the case in this scenario. The
second request failed in various different ways:
- It returned
nullas if the invoice was not created at all. - It returned
401as if the credentials were invalid. - It returned
500due to some unexpected internal error.
A naive implementation might look like the following:
func CreateInvoice(ctx context.Context, api *Client) (*Invoice, error) {
id, err := api.CreateInvoice(ctx, &CreateInvoiceParams{})
if err != nil {
return nil, err
}
invoice, err := api.GetInvoice(ctx, id)
if err != nil {
return nil, err
}
return invoice, nil
}However, this implementation has a major issue: what if api.CreateInvoice succeeds (i.e., the
invoice is created in the third-party system), but api.GetInvoice fails? From the perspective of
the function's call site, it looks like the invoice creation failed, which is incorrect.
How can this problem be solved? It's actually more difficult than it might seem. Any kind of
in-memory retry logic is insufficient because the service may crash or be killed at any time. The
two API calls must be separated and wrapped in their own database transactions, and proper retry
logic must be implemented for the api.GetInvoice call.
The implementation could look something like the following:
func CreateInvoice(ctx context.Context, db *sql.DB, api *Client) error {
tx, err := db.Begin()
defer tx.Rollback()
id, err := api.CreateInvoice(ctx, &CreateInvoiceParams{})
if err != nil {
return err
}
_, err = tx.Exec("INSERT INTO invoices (invoice_ext_id) VALUES ($1)", id)
if err != nil {
// NOTE: this is a fatal error and requires manual handling
return err
}
if err := tx.Commit(); err != nil {
// NOTE: this is a fatal error and requires manual handling
return err
}
return nil
}
// NOTE: this must be retried in case of an error
func GetInvoice(ctx context.Context, db *sql.DB, api *Client, id int) error {
tx, err := db.Begin()
defer tx.Rollback()
invoice, err := api.GetInvoice(ctx, id)
if err != nil {
return err
}
_, err = tx.Exec("UPDATE invoices SET ... WHERE invoice_id = $1", id)
if err != nil {
return err
}
if err := tx.Commit(); err != nil {
return err
}
return nil
}This scenario, in which the process always proceeds in one direction and eventually succeeds, is relatively simple. More complex problems can arise in which some kind of rollback behavior is required. For example, consider the following two operations performed by an e-commerce application:
- Reserve inventory from an
Inventoryservice for an order. - Schedule a shipment for the ordered products with a
Shipmentsservice.
If the Shipments service fails to ship the products due to, for example, invalid customer address
details, the inventory must be released so that another customer can order the same products. In
this case, a rollback mechanism would be needed.
What is the saga pattern?
It is not usually maintainable or time well spent to ad-hoc implement solutions for every individual problem, especially for such a complex and delicate problem as managing distributed transactions. It is essential to have well-designed and robust primitive patterns for commonly encountered problems.
In distributed systems, the saga design pattern allows you to coordinate long-running transactions that span multiple services. It is typically implemented using a series of local transactions, each of which represents a step in the overall transaction. If a local transaction fails, the saga executes a series of compensating transactions to undo the changes made by the preceding local transactions.
Imagine you are building an e-commerce application. You need to be able to receive orders, manage your inventory, ship the ordered products, send a receipt to the customer, and so on. Processing a single order is a sequence of local transactions that may span multiple services. I will use the following flow of operations as a running example throughout this post:
Ordersservice creates a new order for a customer.Inventoryservice reserves the ordered products.Shipmentsservice creates a new shipment for the ordered products.Receiptsservice sends a receipt to the customer.
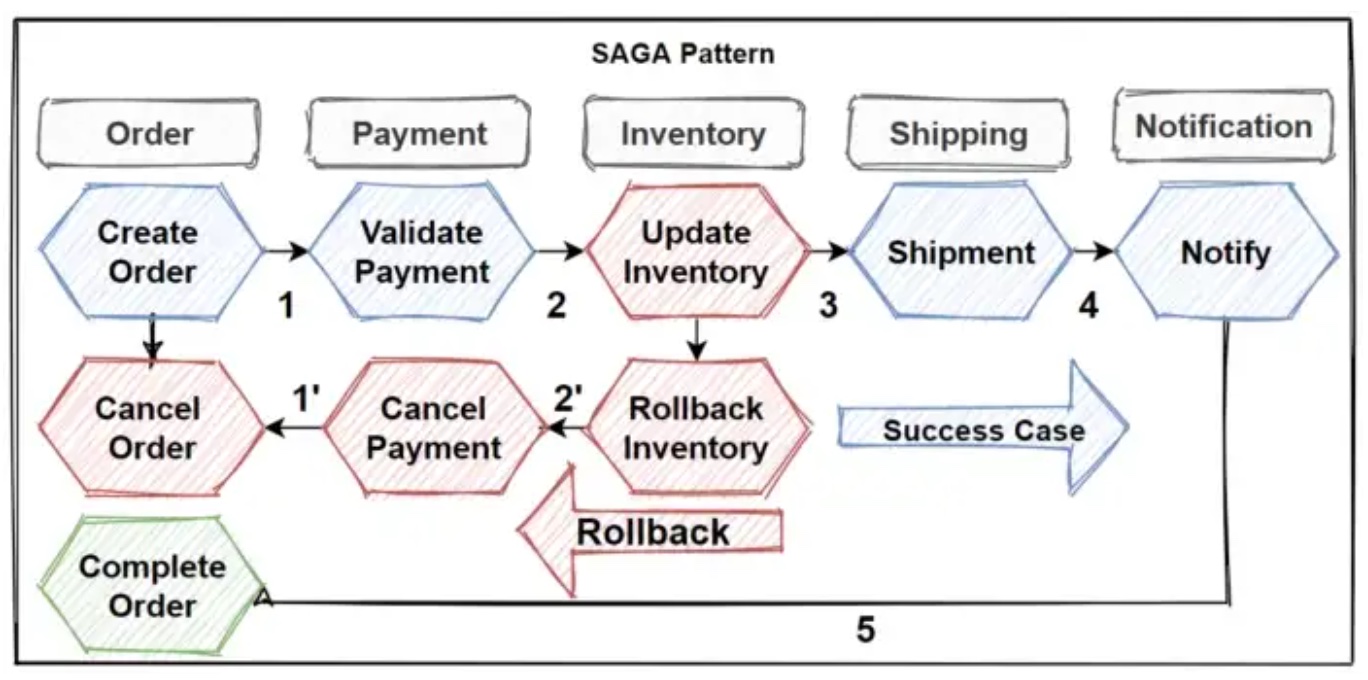 A flow of a saga
A flow of a saga
A single saga is constructed by chaining (action, compensating action) into a sequence of local
transactions, as can be seen in the flow chart above
(source).
The actions are performed in the same order that they are defined. Every task may be retried, but if
any action fatally fails, the saga triggers the compensating actions for the already-performed
actions. For example, consider the following:
Create Orderis triggered and succeeds on the first try.Validate Paymentis triggered:- On the first attempt, payment is unavailable. Scheduled for retry.
- On the second attempt, payment has come through and it succeeds.
Update Inventoryis triggered, but there is no inventory left. It fails fatally.Cancel Paymentis triggered:- On the first attempt, payment service is temporarily down. Scheduled for retry.
- On the second attempt, payment service is still down. Scheduled for retry.
- On the third attempt, customer is successfully refunded.
Cancel Orderis triggered and the order is canceled.
By splitting the order processing into smaller actions, it is possible to do retries and handle failures in a much more controlled way. By being able to define the compensating actions, it is possible to manage fatal failures with expected outcomes.
There is one important limitation to consider: the compensating actions must eventually succeed, and they must be retried until they do.
Implement with Pub/Sub
In this section, we will explore how to use Pub/Sub to implement the saga design pattern. There are two main ways to implement the saga pattern:
- Orchestration. In this approach, a central service orchestrates the execution of actions and triggers compensating actions if needed. Each individual service is only responsible for its own actions.
- Choreography. In this approach, each individual service performs actions associated with their service and publishes the next action for the next participating service to perform. There is no central orchestrating service.
Both approaches have their pros and cons, and there is a great article in the Red Hat's developer blog that compares the two approaches in more detail. In this post, we will focus on the choreography approach.
Actions
Let's first focus only on the actions themselves without the compensating actions. A single action in a saga can be represented as a Pub/Sub message, by either
- using a tree structure for publishing all actions at once. The Pub/Sub message handlers will publish the next action in the queue once the current action has been processed.
- publishing one action at a time, and let every Pub/Sub message handler publish the next action. This assumes that the action Pub/Sub message handlers are aware of the saga's context.
A single individual action can look something like the following:
{
"meta": {
"uuid": "d500c8c2-c639-433e-a572-c6d6bc04511f",
"published_at": "2022-12-23T12:13:09.009211Z"
},
"name": "tasks.create_order",
"payload": {
"customer": {
"uuid": "9a75279b-d817-4fd4-affa-68c224bda1f9"
},
"products": [
{ "uuid": "046c7531-7785-4c57-af0e-c947a5c58284", "quantity": 1 },
{ "uuid": "f0618326-0f1f-48cc-ae17-46b52c448576", "quantity": 3 }
]
}
}Once the published action is processed by the Orders service, the processing code can publish the
next action, such as the tasks.reserve_inventory.
Compensating actions
For a saga to be able to perform the compensating actions on a fatal failure, the compensating actions must somehow be encoded into the action messages. As the compensating actions are to be performed in the reverse order w.r.t. the actions, we can model them with a stack. Consider the following message:
{
"meta": {
"uuid": "d500c8c2-c639-433e-a572-c6d6bc04511f",
"published_at": "2022-12-23T12:13:09.009211Z"
},
"name": "tasks.create_shipment",
"payload": {
"task": {
"customer": {
"uuid": "9a75279b-d817-4fd4-affa-68c224bda1f9"
},
"products": [
{ "uuid": "046c7531-7785-4c57-af0e-c947a5c58284", "quantity": 1 },
{ "uuid": "f0618326-0f1f-48cc-ae17-46b52c448576", "quantity": 3 }
]
},
"rollback_stack": [
{
"name": "tasks.rollback_reserve_inventory",
"task": {
"products": [
{ "uuid": "046c7531-7785-4c57-af0e-c947a5c58284", "quantity": 1 },
{ "uuid": "f0618326-0f1f-48cc-ae17-46b52c448576", "quantity": 3 }
]
}
},
{
"name": "tasks.rollback_create_order",
"task": {
"order": {
"uuid": "55e538a9-ecaa-4a36-bb65-b5202977a894"
}
}
}
]
}
}The action is split into two fields: task and rollback_stack. The task field contains the
current action's payload, with the required information in order to perform the action. The
rollback_stack field contains a stack of the previous actions' compensating actions.
Let's consider the tasks.create_shipment fails. The following message is published:
{
"meta": {
"uuid": "d500c8c2-c639-433e-a572-c6d6bc04511f",
"published_at": "2022-12-23T12:13:09.009211Z"
},
"name": "tasks.rollback_reserve_inventory",
"payload": {
"task": {
"products": [
{ "uuid": "046c7531-7785-4c57-af0e-c947a5c58284", "quantity": 1 },
{ "uuid": "f0618326-0f1f-48cc-ae17-46b52c448576", "quantity": 3 }
]
},
"rollback_stack": [
{
"name": "tasks.rollback_create_order",
"task": {
"order": {
"uuid": "55e538a9-ecaa-4a36-bb65-b5202977a894"
}
}
}
]
}
}Once the tasks.rollback_reserve_inventory has succeeded, the following message is published:
{
"meta": {
"uuid": "d500c8c2-c639-433e-a572-c6d6bc04511f",
"published_at": "2022-12-23T12:13:09.009211Z"
},
"name": "tasks.rollback_create_order",
"payload": {
"task": {
"order": {
"uuid": "55e538a9-ecaa-4a36-bb65-b5202977a894"
}
},
"rollback_stack": []
}
}Observability
Any distributed system or operation is hard to monitor and debug. Hence, it is important to think about observability and build it right into the solution from the very start. Specifically for sagas, one should be able to see a holistic view into the entire end-to-end execution of all actions and their potential compensating actions. You must be able to associate the local operations into a single saga, see the failed attempts, and so on. Tracing is a great tool for this.
Normally, a trace gives us the big picture of what happens during a request made by a user or an application. A trace consists of a number of spans, which represent a unit of work. A single trace usually consists of the operations made during a synchronous request; it begins when a request comes in and ends when the response is sent out.
For sagas, we have to be able to associate asynchronous actions to each other. With OpenTelemetry, you can use either parent-child relationships or link relationships to represent the flow of a saga through a system.
Using parent-child relationships:
- Each step in the saga can be represented by a span, with the parent-child relationship indicating the flow of the saga through the system.
- This approach is useful if you want to represent the flow of the saga as a single logical operation, with each step in the saga represented as a span within the trace.
Using link relationships:
- Each step in the saga can be represented by a separate trace, with link relationships used to link the traces together.
- This approach is useful if you want to represent each step in the saga as a separate logical operation, with the link relationships indicating the relationships between the different traces.
Which approach you choose will depend on your specific requirements and how you want to represent the flow of the saga through the system. I chose to go with the parent-child relationship approach because it seems to be better supported by different tools.
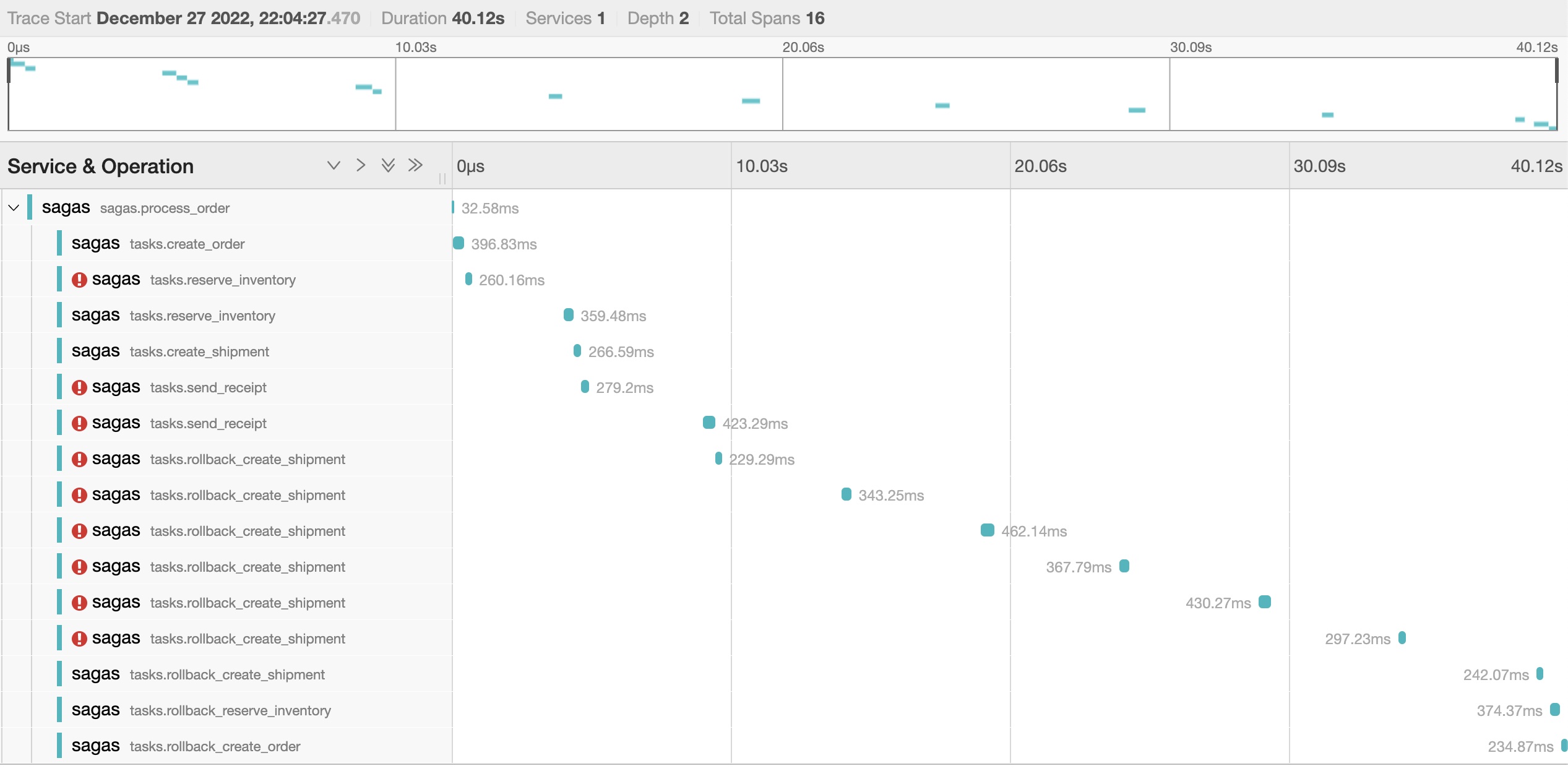 An example saga visualised in Jaeger
An example saga visualised in Jaeger
In the picture above, you can see an execution of a saga. You can also see the failed attempts, their retries, and the rollback behaviour.
Associating the saga's actions to a single trace is quite straightforward as OpenTelemetry client libraries support propagating the trace context. This is how, for example, OpenTelemetry instruments regular HTTP requests made between services and associates the spans to the same trace.
First, we should add the ability to inject metadata into the Pub/Sub messages:
{
"meta": {
"uuid": "d500c8c2-c639-433e-a572-c6d6bc04511f",
"published_at": "2022-12-23T12:13:09.009211Z"
},
"name": "tasks.create_shipment",
"payload": {
"meta": {
"traceparent": "00-20b7bf8128563e14b03daa594a564edf-85e02d0ab3e3266d-01"
},
"task": {
"customer": {
"uuid": "9a75279b-d817-4fd4-affa-68c224bda1f9"
},
"products": [
{ "uuid": "046c7531-7785-4c57-af0e-c947a5c58284", "quantity": 1 },
{ "uuid": "f0618326-0f1f-48cc-ae17-46b52c448576", "quantity": 3 }
]
},
"rollback_stack": []
}
}By injecting the traceparent into every action's metadata, the handling code can extract the trace
context from the message and start a new span as a child of the saga's trace.
Implementation
For the Pub/Sub implementation, I will be using a library that I previously wrote. You can find the library on Github at markusylisiurunen/go-opinionatedevents and a related blog post here.
In this section, I will go through some of the most interesting parts of the implementation. The full example can be found on Github at markusylisiurunen/go-sagas-example.
First, I defined a new middleware which handles rollbacks after n failed attempts:
func WithRollback[Message any, MessagePtr interface {
TaskMessage
*Message
}](
publisher *opinionatedevents.Publisher, limit int,
) opinionatedevents.OnMessageMiddleware {
rollback := func(
ctx context.Context, delivery opinionatedevents.Delivery,
) opinionatedevents.ResultContainer {
msg := MessagePtr(new(Message))
if err := delivery.GetMessage().Payload(msg); err != nil {
return opinionatedevents.FatalResult(err)
}
rollback, ok := msg.Rollback()
if !ok {
// the rollback stack is empty (the action itself should still fail)
err := errors.New("processing the task failed, nothing to roll back")
return opinionatedevents.FatalResult(err)
}
if err := publisher.Publish(ctx, rollback.GetOpinionated()); err != nil {
return opinionatedevents.ErrorResult(err, 2*time.Second)
}
// the rollback message was published successfully (the action itself should still fail)
err := errors.New("processing the task failed, rolling back")
return opinionatedevents.FatalResult(err)
}
return func(next opinionatedevents.OnMessageHandler) opinionatedevents.OnMessageHandler {
return func(
ctx context.Context, queue string, delivery opinionatedevents.Delivery,
) opinionatedevents.ResultContainer {
if delivery.GetAttempt() > limit {
return rollback(ctx, delivery)
}
result := next(ctx, queue, delivery)
if result.GetResult().Err != nil && result.GetResult().RetryAt.IsZero() {
// fatal error, should roll back immediately
return rollback(ctx, delivery)
}
if result.GetResult().Err != nil && delivery.GetAttempt() >= limit {
// retriable error, but has failed too many times
return rollback(ctx, delivery)
}
return result
}
}
}Next, a single action's handler is defined as:
receiver.On("default", "tasks.create_order",
opinionatedevents.WithBackoff(opinionatedevents.LinearBackoff(2, 3, 15*time.Second))(
message.WithRollback[message.TaskCreateOrder](publisher, 4)(
func(ctx context.Context, _ string, delivery opinionatedevents.Delivery) opinionatedevents.ResultContainer {
msg := &message.TaskCreateOrder{}
if err := delivery.GetMessage().Payload(msg); err != nil {
return opinionatedevents.FatalResult(err)
}
return handleTaskCreateOrder(ctx, publisher, msg)
},
),
),
)There are two middlewares:
- Backoff, which schedules the retries according to a backoff function.
- Rollback, which publishes the rollback message from the rollback stack.
A rollback message handler is mounted in a similar way, but without the WithRollback middleware.
Rollback messages should be retried until they are successfully processed.
Injecting and extracting the trace context is implemented as follows:
type message struct {
Meta map[string]string `json:"meta"`
// ...
}
func (m *message) Inject(ctx context.Context) {
carrier := propagation.MapCarrier{}
otel.GetTextMapPropagator().Inject(ctx, carrier)
m.Meta = carrier
}
func (m *message) InjectFromMessage(msg Observable) {
m.Inject(msg.Extract(context.Background()))
}
func (m *message) Extract(ctx context.Context) context.Context {
if m.Meta == nil {
return ctx
}
carrier := propagation.MapCarrier(m.Meta)
return otel.GetTextMapPropagator().Extract(ctx, carrier)
}Whenever an action handler creates its span, it should extract the context from the message:
_, span := otel.Tracer("sagas").Start(msg.Extract(ctx), "create order")
defer span.End()Similarly, whenever an action handler publishes a new action, it should inject the trace context from the previous message:
task := message.NewTaskReserveInventory("...")
task.InjectFromMessage(msg)